The journey so far (pt1, pt2) has led us from geeky twinkle in my eye, to a load of servers sat in a very environmentally concious (if you ignore the power requirements) rack. Now is where things get serious, now we actually do something with all that silicon muscle. Brains. Whatever.
I had some initial requirements for my home setup. I needed all that storage available as a big ol’ network share. Some sort of data redundancy would be nice (RAID / parity) preferably ZFS. I needed to be able to run containers on it in a straightforward fashion. Virtual machine capabilities would be nice, although I don’t have any requirement for full blown virtual machines at present at some point I might investigate running a headless desktop on there. Clustering those capabilities seems sensible since I have 3 servers and it’s always good to play around with new things.
Being fairly lazy, I first started with proxmox, which all the cool ‘home-labbers’ (home-labitters? Home-lab techs? whatever) seem to love:
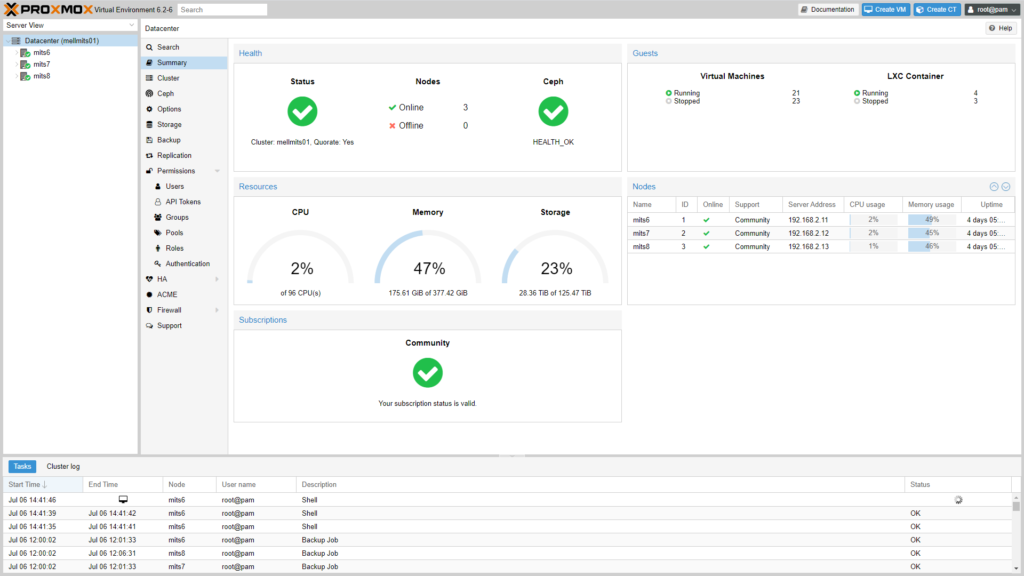
And to be fair it has a lot going for it. It supports clustering out of the box, there’s a free version which is always good, it seems very ‘VM’ focussed, but there is support for containers and so on and so forth. Unfortunately I tried proxmox when I was messing around with my fibre channel SAN thing, and due to the fibre channel card being bobbins I had real issues with stability. I know, nothing to do with proxmox, but I just never went back to it once I had everything stable. Also, the container support here is a bit…second class citizen. You can use containers, but they’re LXC rather than docker-esque ones. So you get a lot of the same functionality, without the ‘basically, everyone is using this’ benefits of docker. Also, it looks very…enterprisey. Again, not a sensible reason for making a software choice, but hey this is for my home setup so I’m allowed to be irrational about my choices.
Next I took a look at Truenas Scale:
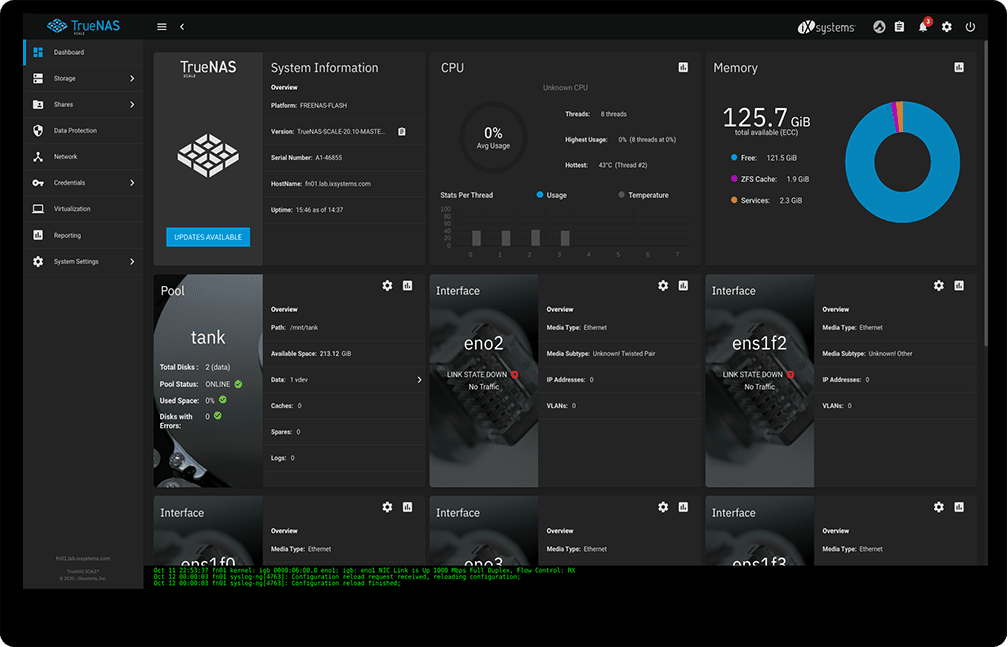
This is actually really promising. It’s based on Freenas, which I’ve used in the past (only now it’s merged with Truenas? Or something). It supports ZFS and Kubernetes to form a ‘hyper-converged’ cluster! Or that’s the intention anyway, unfortunately it’s still in Alpha stage and really just getting started on the kubernetes support. So sometime later this year it might be amazing…as it stands at the moment, it’s more for developers and so on.
Eventually then I settled on…….. (drumroll please) Debian!
Yup, after trying all of the fancy guis and abstractions I decided to go back to basics and actually figure out how to set up a kubernetes cluster from scratch. And….it’s surprisingly easy! There’s a helper program (kubeadm) and, as long as you meet the pre-requisites, it really is as simple as typing a few commands and marvelling at your new cluster. Check out the documentation here and give it a whirl.
Of course, one of the best & worst parts of the vanilla kubernetes experience is how unopinionated it is out of the box. Want a networking layer? (hint: you do), well there’s plenty to choose from….flannel, calico etc, and no real indication which is ‘better’ or more suitable for what you’re trying to do. The general principles seem to be that vendors (ie: the redhats of the world) are free to sell opinionated versions of kubernetes with all of these decisions made for you, but if you want to go it alone you have to….well, go it alone. Here’s some notes on the choices I made along the way to get to where I am now:
Networking: I went with calico. I did try flannel initially, but for some reason I couldn’t get it to work (probably more my fault than anything else, it was one of the first things I tried to do after setting a cluster up) so tried calico and got it up and running pretty quickly. Just download the yaml file from here and note the part about the CIDR on there. I ignored that first time and ended up with broken networking. See where it says it can autodetect your CIDR? I found that to be not entirely accurate. To be safe, edit the manifest you download, uncomment the ‘CALICO_IPV4POOL_CIDR’ variable and set it to something that doesn’t conflict with your host network!! My hosts are in the 192.168.100.0/24 range and, by default, calico gave my pods IPs in the range 192.168.0.0/16 or something. I set it to ‘10.0.0.0/16’ instead to great success. Oh you might need to change the IP of your kube_dns pod to something in that range as well, so edit /var/lib/kubelet/config.yaml and set the ‘clusterDNS’ field to ‘10.96.0.10’. Restart kubelet, kill your coredns pod(s) and they should restart with the new IP.
Ingress: I picked Kong. I just went for the simplest manifest I could find (this one in fact) and it was up and running no problem. It’s the db-less version, so I can’t install plugins for authentication etc but for my simple home cluster it does what I need it to. There’s also a manifest for the fancy postgres version here if you’re that way inclined.
For storage I use a mix of Gluster and the old faithful, Samba. I was originally going to run everything over samba, but I had issues with things like grafana getting upset about file locks on its internal database, so needed something with support built into kubernetes. I now run a gluster cluster (heh) on my local disks, with number of replicas set to number of machines (so every machine has the full dataset basically) and use samba just for things I download off the internet. Oh you know, just things. And Stuff. For samba shares, I use this handy flexvolume plugin, but because I need to connect to an unauthenticated share (I know, it’s horrible, but it’s also behind my internal firewall and doesn’t have anything on it that I couldn’t stand to lose) I grabbed the file from this Pull request which adds the ‘guest’ option.
So, that’s the basics of my cluster. Currently it’s doing very little, running a security camera through motioneye, some prometheus reporting and, oh yes, this website. Next time (which given how regularly I’m getting these out, will be in about 2 months time I expect) I’ll go into some detail about how I deploy things to my cluster direct from git and some stuff about monitoring with prometheus.
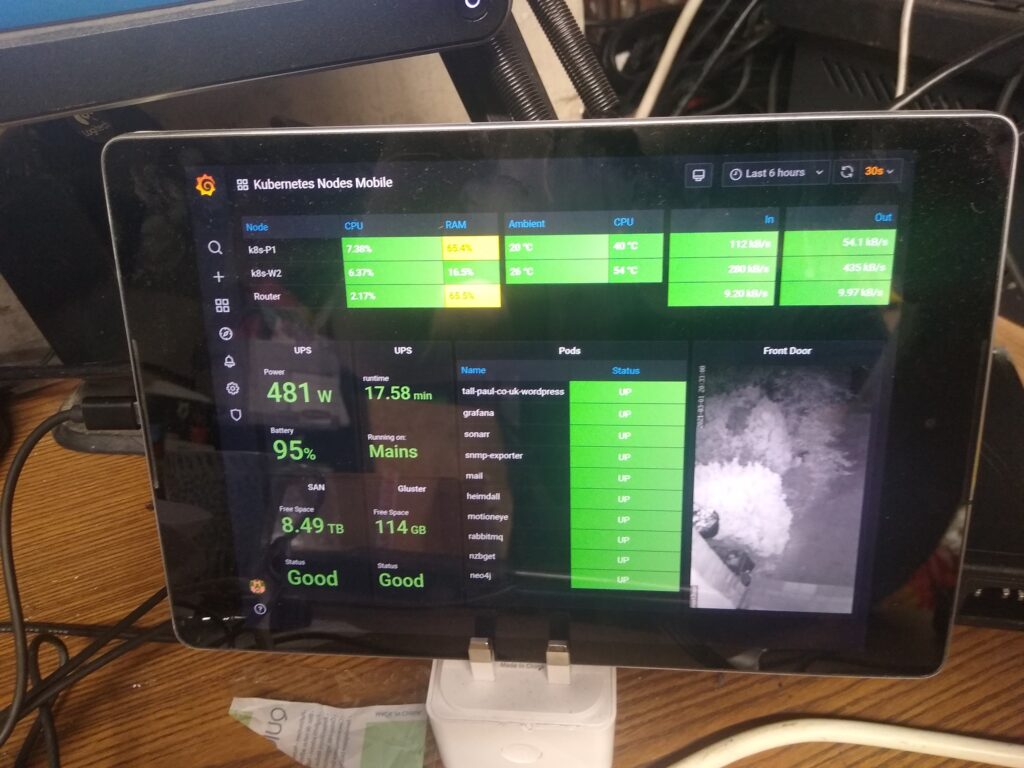
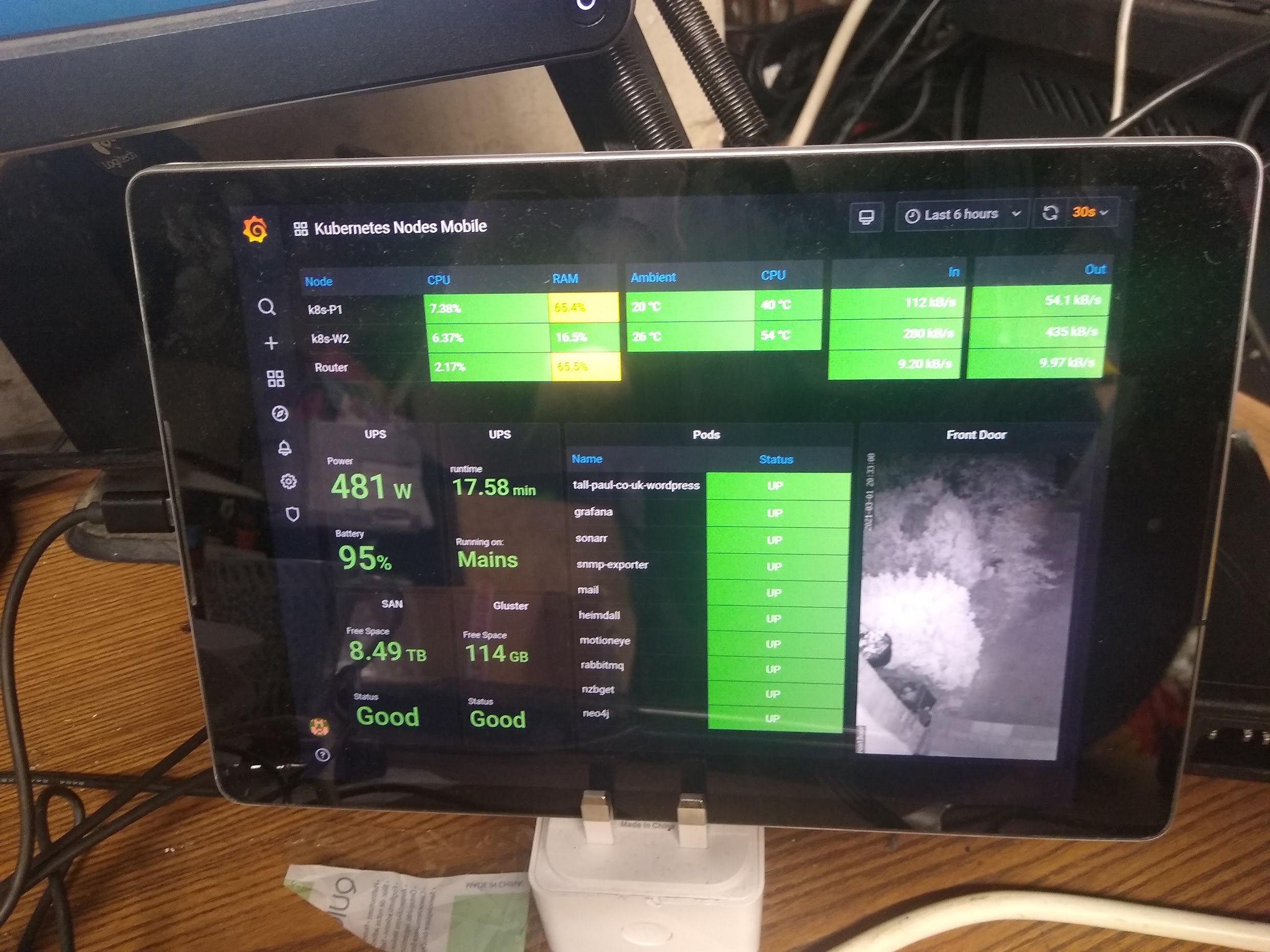
In the meantime, enjoy this glamour shot of my monitoring dashboard and its high tech mounting system: